Joint Spatial and Layer Attention for Convolutional Networks
Faculty of Science
University of Ontario Institute of Technology
2000 Simcoe St. N., Oshawa ON L1G 0C5
Department of Computer Science
Ryerson University
350 Victoria St, Toronto, ON M5B 2K3
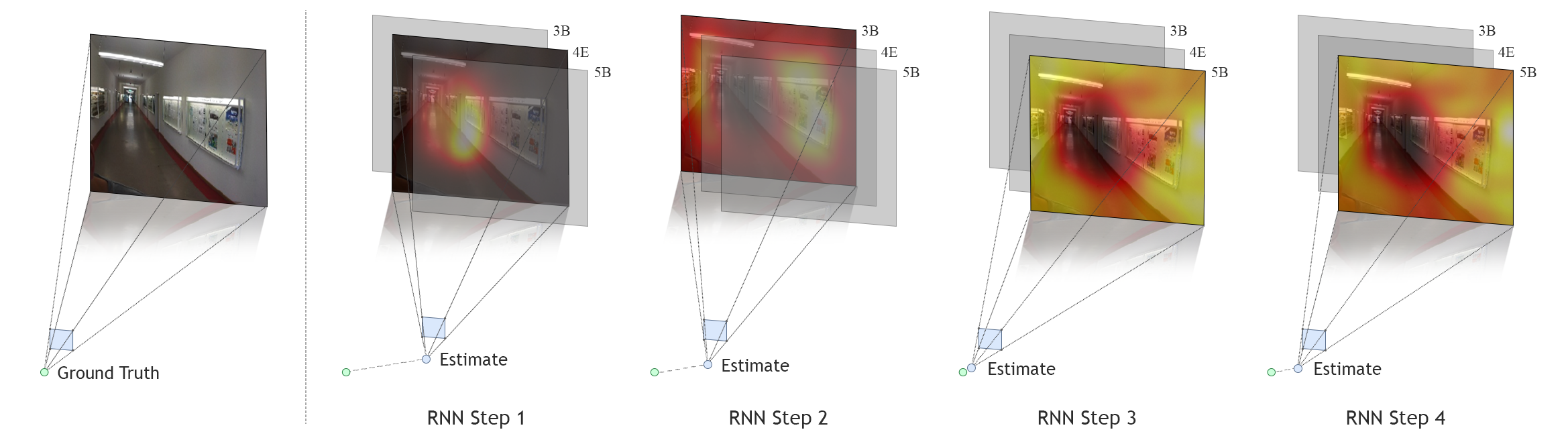
Abstract
In this paper, we propose a novel approach that learns to sequentially attend to differentConvolutional Neural Networks (CNN) layers (i.e., “what” feature abstraction to attend to) and different spatial locations of the selected feature map (i.e., “where”) to performthe task at hand. Specifically, at each Recurrent Neural Network (RNN) step, both a CNN layer and localized spatial region within it are selected for further processing. We demonstrate the effectiveness of this approach on two computer vision tasks: (i) image-basedsix degree of freedom camera pose regression and (ii) indoor scene classification. Em-pirically, we show that combining the “what” and “where” aspects of attention improvesnetwork performance on both tasks. We evaluate our method on standard benchmarks forcamera localization (Cambridge, 7-Scenes, and TUM-LSI) and for scene classification(MIT-67 Indoor Scenes). For camera localization our approach reduces the median errorby 18.8% for position and 8.2% for orientation (averaged over all scenes), and for sceneclassification it improves the mean accuracy by 3.4% over previous methods.
BMVC 2019 Poster
Supplementary Material
Supplementary material is available here.
Publication
For technical details please look at the following publications