Video Summarization
Faculty of Science
University of Ontario Institute of Technology
2000 Simcoe St. N., Oshawa ON L1G 0C5
Cameras are now ubiquitous. This has resulted in an explosive growth in user-generated images and videos. In the case of videos, at least, our ability to record videos has far outpaced methods and tools to manage these videos. A skier, for example, can easily record many hours of video footage using an action camera, such as a Go-Pro. Raw video footage, in general, is unviewable—the recorded video needs to be summarized or edited in some manner before it can be shared with others. Clearly, no one is interested in watching many hours of skiing video when most of it is bound to be highly repetitive. Manual video editing and summarizing is painstakingly slow and tedious. Consequently a large fraction of recorded footage is never shared or even viewed. We desperately need one-touch video editing tools capable of generating video summarizes that capture the meaningful and interesting portions of the video, dis- carding sections that are boring, repetitive or poorly recorded. Such tools will revolutionize how we share video stories with friends and family via social media.
These observations has led us to explore new theory and methods for video summarization.
Real-time Video Summarization on Commodity Hardware
If you have trouble seeing this video, you can download it here.
Abstract
We present a method for creating video summaries in real-time on commodity hardware. Real-time here refers to the fact that the time required for video summarization is less than the duration of the input video. First, low-level features are use to discard undesirable frames. Next, video is divided into segments, and segment-level features are extracted for each segment. Tree-based models trained on widely available video summarization and computational aesthetics datasets are then used to rank individual segments, and top-ranked segments are selected to generate the final video summary. We evaluate the proposed method on The SumMe Video Summarization (SumMe) dataset and show that our method is able to achieve summarization accuracy that is comparable to that of a current state-of-the-art deep learning method, while posting significantly faster run-times. Our method on average is able to generate a video summary in time that is shorter than the duration of the video.
Publication
Automatic Video Editing for Sensor-Rich Videos
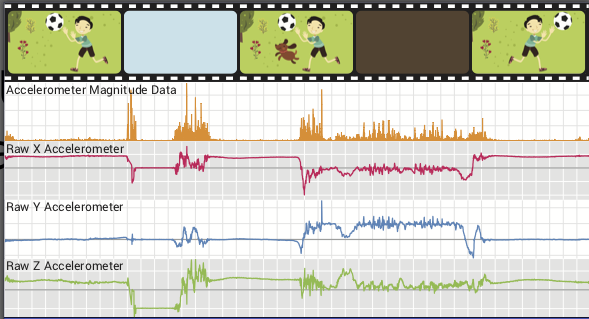
You can check out the sensor data recorded for a number of videos below. Each file is a PDF containing sample frames for each final cut, along with plots of all available data.
Abstract
We present a new framework for capturing videos using sensor-rich mobile devices, such as smartphones, tablets, etc. Many of today’s mobile devices are equipped with a variety of sensors, including accelerometers, magnetometers and gyroscopes, which are rarely used during video capture for anything more than video stabilization. We demonstrate that these sensors, together with the information that can be extracted from the recorded video via computer vi- sion techniques, provide a rich source of data that can be leveraged to automatically edit and “clean up” the captured video. Sensor data, for example, can be used to identify un- desirable video segments that are then hidden from view. We showcase an Android video recording app that captures sensor data during video recording and is capable of automatically constructing final-cuts from the recorded video. The app uses the captured sensor data plus computer vision algorithms, such as focus analysis, face detection, etc., to filter out undesirable segments and keep visually appealing portions of the captured video to create a final cut. We also show how information from various sensors and computer vision routines can be combined to create different final cuts with little or no user input.